RDMA: Bypassing the Kernel for Network I/O
RDMA lets one machine read and write another machine's memory, the network card handles it, and the remote CPU doesn't even know it happened.
That sounded wrong to me at first. I knew the slogan, "skip the kernel, go fast," but I didn't understand what it meant at the hardware level.
what's wrong with normal networking
When you use TCP, the kernel is always involved. The app calls send(), which is a syscall, so execution enters the kernel; your data gets copied from the app buffer to a kernel buffer, TCP runs its state machine (checksum, segmentation, queueing), and eventually the driver sends it to the NIC.
Receive side is the same thing: NIC gets packet, interrupt, kernel wakes up, copies to socket buffer, and then the app calls recv() which triggers another copy into the app buffer. So you end up with two copies, multiple syscalls, and context switches every time, and the CPU stays busy with all of it.
If you're moving big files, it's OK because the overhead doesn't matter much. But if you want millions of small operations per second (like key-value gets), this overhead is too much.
what rdma does different
With RDMA, the network card reads and writes directly to your app memory. When you send, the NIC reads from your buffer via DMA, and when you receive, it writes into your buffer via DMA, so the kernel is off the fast path and the extra copies disappear.
There's also one-sided operations: RDMA_WRITE puts bytes into remote memory and RDMA_READ pulls bytes from it, while the remote CPU keeps running because nobody wakes it up. First time I saw this it looked strange, you're writing to memory on a different machine, through the network card, and that machine doesn't know it happened.
"Doesn't know" means the remote CPU isn't interrupted and doesn't execute any code. But the NIC is still doing DMA over PCIe, which consumes memory bandwidth on the remote machine. At high throughput, one-sided RDMA operations can noticeably affect remote-side performance even though no software runs there.
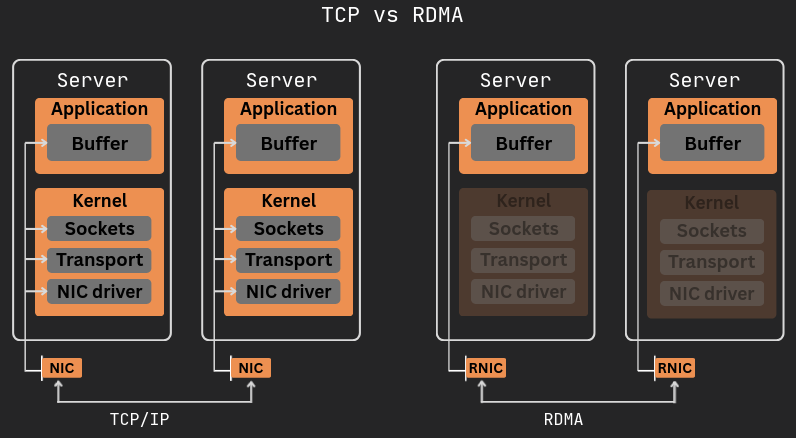
setup vs data path
The kernel is still there, just not on the data path. Before you send anything, you have to set things up by opening the device, creating queues, registering memory, and connecting to the remote side, and all of this goes through syscalls and kernel checks.
Only after setup does the fast path work, where you post work directly to hardware and poll completions without syscalls for that part. So the trade is expensive setup but cheap operations after, which is good if you do many operations and not good for connections that don't last.
queue pairs
RDMA doesn't use sockets, it uses queues instead. A Queue Pair is your connection, and it has a send queue and a receive queue where you put work requests saying what to do (send this buffer, read from that address), and the NIC processes them when it can.
A Completion Queue is how you know things finished: the NIC puts entries there and you poll or wait.
The annoying thing is that queue pairs start in RESET state and must move through RESET → INIT → RTR → RTS, and if you miss one transition nothing works and you usually don't get a useful error, which took me a while to learn the first time.
memory registration
Before the NIC can touch your memory, you register it. What registration does is pin the pages so memory can't go to swap (physical addresses stay valid because the hardware will DMA there), build a translation in the NIC so it knows where virtual address X is in physical memory, and give you keys (lkey for your own ops, rkey to share with the remote side so they can access your memory).
Registration is a syscall, and this is where the kernel checks permissions.
who checks if not kernel
This part confused me for a while. With normal networking the kernel validates everything: bad pointer gives you SIGSEGV, wrong permission gives you an error, the kernel is the one checking. But with RDMA the kernel is not in the data path, so how do bad accesses get stopped?
The answer is hardware. When you register memory, the kernel tells the NIC which addresses are valid and what permissions they have and which protection domain they belong to, and the NIC stores all this in its memory protection tables. Then during transfers the NIC checks every operation: is the address in a registered region, are the permissions OK, does the key match. If something is wrong, the operation fails and the error shows up in the completion queue (not SIGSEGV, because the NIC caught it, not the CPU). Hardware does what the kernel would do, just at wire speed.
protection domains
You can't access anyone's memory. A Protection Domain is a security boundary: when you make a queue pair and register memory, you put them in a PD, and operations only work on memory in the same PD. This is like kernel process isolation but for RDMA, where different apps get different PDs.
one-sided and two-sided
There are two kinds of operations. Two-sided means both sides do something: the receiver posts a buffer first, the sender posts a send, and both CPUs are involved. One-sided means only you do something: RDMA_WRITE pushes data to remote memory, RDMA_READ pulls data, and the remote CPU is not involved, not even aware.
One-sided is where RDMA is really powerful, but it's also more work because if the remote app needs to know you wrote, you have to tell it somehow. Usually you write a flag that it polls, or use atomics, and synchronization becomes your problem to solve.
atomics
There are atomic operations (compare-and-swap and fetch-and-add) that run at remote memory, atomically, without involving the remote CPU. Good for locks and counters, but slower than regular read/write, and some NICs implement them in firmware so even slower. Depends on the card.
the hardware
You need a special NIC because normal ones don't do RDMA.
InfiniBand is the original, it needs its own switches and cables, has very low latency (under a microsecond), and HPC clusters use it. RoCE is RDMA over Ethernet, which works on regular switches, but Ethernet drops packets and RDMA really doesn't like that, so you configure switches for "lossless" mode with priority flow control and so on, and it gets complicated. iWARP is RDMA over TCP, which is the most compatible option, but TCP adds latency. I think most datacenters use RoCE v2 now.
some numbers
| What | How long |
|---|---|
| TCP round trip | 10-50 μs |
| RDMA round trip | 1-5 μs |
| Local memory | ~100 ns |
RDMA is maybe 10x faster than TCP, but still 10x slower than local RAM. This is important when you think about memory disaggregation because you're replacing local memory with remote, and microseconds add up.
what's hard about it
Debugging is not fun because problems show up as completion queue errors with codes you have to look up, there's no tcpdump, and when something breaks you look at hardware counters and guess.
Before RDMA works, both sides have to exchange info (queue pair numbers, memory keys, addresses), and usually you do this over TCP first, which is extra complexity. Registered memory is pinned, so big registrations hit ulimit. For two-sided operations, the receiver must post buffers before the sender sends, and if the receiver runs out of buffers the sender's operations fail.
notes
- Verbs API is standard interface. libibverbs on Linux.
- Watch
ulimit -lfor locked memory limit. - One app can have many queue pairs and completion queues. Common pattern is one QP per thread.
- Atomic ops: compare-and-swap, fetch-and-add. Support varies by hardware.
- Paper: RDMA is Turing complete (yes really)
- Man pages: ibv_create_qp, ibv_reg_mr, ibv_post_send
- Nvidia docs: RDMA Aware Networks Programming User Manual